Moving codes to Exascale has hidden costs that we shall evaluate
It is now well known that reaching the Exascale is, for the HPC ecosystem, not a change of magnitude but a paradigm shift, which includes programming the upcoming exascale machines and porting existing codes to achieve the performance gains expected with supercomputers delivering 1018 FLOPS.
While efforts have been concentrated on hardware, the cost of porting current application codes to the next generation of HPC systems is seldom studied nor included and thus underestimated.
A recent US survey calculated that rewriting a line of code costs around 10€[1]. With millions of lines to treat both for academia and industry, and the announced arrival of European exascale machines around 2022, there is a need to assess the costs of porting our codes at the European level. This question shall be addressed now as updating large codes takes time: it will be a multi-year effort, probably in the order of 5 to 10 years for the largest ones.
Underestimating those efforts will have multiple consequences: important delays to achieve the porting, loss of leadership or attractiveness of European research teams, economic losses for European industrials in an ever more competitive world, to name a few.
That is why EXDCi-2 has set-up a working group to analyse the European code legacy towards the Exascale. Guillaume Colin de Verdière explains the method and actions taken by this EXDCI-2 working group, which includes the creation of new metric (Code Viscosity) and its display through a European survey that will be the basis for a global evaluation of the efforts that will be required to port EU codes to the next generation of machines.
Code Viscosity: a simple metric to evaluate code legacy
Code Viscosity is a simple yet robust metric based on four parameters (Age and Length of code; Percentage of its acceleration; Team capability and confidence to port it) that was created by the EXDCI-2 working group to exhibit trends and help to determine extra migration costs to Exascale.
“When we started our work on evaluating the efforts required to move European codes to Exascale, we soon faced the problem of defining the complexity of this migration and to build a common metric to address a wide diversity of situations. If we look at the European richness of HPC applications, we knew that we would have to address and compare a large variety of cases.
As a first action, we selected universal parameters that take into account the main difficulties faced by a development team in migrating codes to the next generation of machines. Those parameters needed to be easily determined by the concerned software development teams, also for our survey to be less time consuming and thus to collect broader answers from the European HPC ecosystem. Simplicity was the key, which, in return, means that our metric would not be highly sophisticated, yet strong enough for our evaluation purposes.
We retained four parameters to define our metric:
- The age of the code in years – named A
- The length of the source code, in millions of lines, excluding third party libraries such as BLAS, FFTW – named L
- The team capability or confidence to develop accelerated codes. This parameter is an estimation made by the concerned team and its value goes from 0 – the team cannot port the code – to 1 – the team has the expertise and skills to perform the job. This parameter is named TC
- The percentage of acceleration, from 1 for a code fully ported to accelerators to 0 for code not ported at all – named P
With these four parameters, we created our metric that we named code Viscosity by analogy to the viscosity of a fluid that quantifies its resistance to movement. The more viscous a code, the more expensive it will be to do the port, both in terms of time to completion and in the manpower needed, the less it is prone to the adoption of newer technologies. In other words the more viscous, the higher the technical debt of the code that will have to be paid sometime in the future.
Code Viscosity – named V – is defined by the following formula:
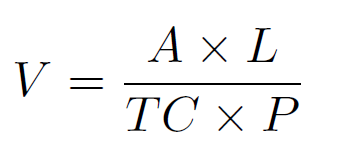
Code Viscosity: example of values
“In the following table, the EXDCI-2 working group illustrates this metric with values chosen to test the code Viscosity that reflect exemplary use cases based on some real situations.
|
Use Case Description |
Age |
Length |
Team Capability |
Percentage of acceleration |
Code Viscosity Value |
|
A young code (1 year) is ported by an unexperienced team |
1 |
1 |
0.001 |
0.1 |
10000 |
|
A young code (1 year), optimized for accelerators since the beginning. The team is fairly skilled and experienced |
1 |
2 |
0.5 |
1 |
4 |
|
A medium age code (5 years) with few optimization for accelerators and a fully skilled team |
5 |
2 |
1 |
0.5 |
20 |
|
A small (100k lines) medium age code (5 years), optimized from the beginning with a fully skilled team |
5 |
0.1 |
1 |
1 |
0.5 |
|
A legacy code (10 years) modestly accelerated. Confidence to change the legacy code is limited |
10 |
3 |
0.3 |
0.3 |
333 |
|
A legacy code (20 years) that has been not optimized. Confidence to port it is very limited |
20 |
4 |
0.1 |
0.001 |
800000 |
High Viscosity values are due to the choice of limit values for the denominators, which will help us detect critical cases. The survey will help to determine the proper separation value between codes easy to port to Exascale systems and those who need some form of investment“.
Legacy codes: a fragile yet crucial heritage
Legacy codes are old codes that are vital for their organizations. They concentrate difficulties with foreseen high viscosity level and should be scrutinized with care.
“In our study, we use the concept of legacy code which forms a specific group of applications that should be scrutinized with more attention. A legacy code is a code that is too important to fail. Legacy codes are defined by three parameters: they are old codes – e.g more than 10 years old – they are vital to their organizations and they must be ported to the new generation of machines.
Legacy codes are not specific to HPC – banks and insurance companies for example still use old codes that they cannot replace. In 2015, the MIT technology review estimated that the oldest computer program still in use in the US was MOCAS, written in COBOL, implemented as far as 1958, 61 years ago and more than 10 years before Apollo landed on the moon…
Due to their characteristics legacy codes are particularly vulnerable when it comes to migrating to a new generation of machines. During their lifetime, these codes go through several generations of computers, several generations of programming environments, several standards used, several generations of software developers and are manipulated by changing teams over time. All these layers strongly impact the viscosity measure of a legacy code.
Legacy codes are not a new subject for the HPC centres: they already face these issues with codes in FORTRAN, but as time goes, we noticed that codes in C started to join the legacy code category.
In our study, we will pay a particular attention to the legacy code category as critical assets for which extra efforts may be foreseen when it comes to migrating to the Exascale.”
Next steps: Evaluate the European HPC viscosity distribution
Nobody knows what the viscosity’s distribution of actual codes will be. Our survey will attempt to determine the resources that shall be mobilized to migrate to the Exascale and thus propose adequate measures for critical issues.
The viscosity metric can also interest the other HPC ecosystems which face the same issues as in Europe, e.g Japan, USA and China.
“The next step of our EXDCI-2 working group is to conduct a wide survey with the European HPC ecosystem that will allow us to evaluate the distribution of the EU codes’ viscosity with a specific attention on legacy codes.
At this point of our work, we expect a gaussian distribution of the vital codes’ viscosity with a first pool of small codes with a low measure, and thus easy to port, a second large pool of somewhat more viscous codes and a third pool of codes with high level of viscosity. However, this can be just prevision as, at this stage, nobody knows what the results of our study will be.
With this evaluation, we will be able to estimate the resources needed to migrate our codes for the Exascale era and propose accompaniment such as relying on CoE (centres of excellences), advice or mitigation measures depending on critical efforts to be made to address the migration challenge.
Moreover if EXDCI-2 objectives are focused on European code heritage, this matter is of interest at a global level and the code Viscosity metric could easily be used worldwide.”
EXDCI-2 working group on legacy codes
EXDCI-2 working group on legacy codes is led by Guillaume Colin de Verdière (CEA), with the help of François Bodin (Rennes 1 University and EXDCI-2 scientific coordinator) and Maike Gilliot (Teratec – ETP4HPC), with special thanks to Bernd Mohr (Juelich)
About Guillaume Colin de Verdière

Guillaume Colin de Verdière, PhD, International Expert at CEA (Commissariat à l’énergie atomique et aux énergies alternatives).
Guillaume graduated from ENSCP (Chimie ParisTech) in 1984 and got his PhD in 2019. He has been a CEA staff member since 1985. After contributing to large scientific codes for 7 years, he has been deeply involved in post-processing software with a focus on visualization and I/O. Since 2008, his activities are on investigating new architectures for next generations of supercomputers and foresee the impact of such architectures on scientific codes.
[1] http://csse.usc.edu/new/wp-content/uploads/2014/10/Software-Cost-Estimation-Metrics-Manual-for-Defense-Systems-6.pdf . 300 LOC/month 3000€/month/developer = 10€/LOC.